


さらなる処理の前に外れ値を除去するために、データセットのおおよそのパーセンタイル (順序統計) を繰り返し計算する必要があるプログラムがあります。現在、値の配列を並べ替えて適切な要素を選択することでこれを行っています。これは実行可能ですが、プログラムのかなり小さな部分であるにもかかわらず、プロファイルでは顕著な変化となります。
より詳しい情報:
- データ セットには、最大 100000 個の浮動小数点数が含まれており、「合理的に」分布していると想定されています。つまり、特定の値の近くで重複したり、密度が急激に上昇したりする可能性は低いということです。また、何らかの理由で分布が異常な場合は、データがとにかく混乱していて、それ以上の処理が疑わしいため、近似値の精度が低くても問題ありません。ただし、データは必ずしも均一または正規分布しているわけではなく、退化する可能性は非常に低いだけです。
- おおよその解決法でもいいのですが、理解する必要があるのはどうやって近似値が有効であることを保証するために誤差が導入されます。
- 目的は外れ値を除去することなので、常に同じデータに対して 2 つのパーセンタイルを計算します。たとえば、1 つは 95%、もう 1 つは 5% です。
- アプリは C# で書かれており、C++ で少し重い処理がされています。どちらかの疑似コードまたは既存のライブラリでも問題ありません。
- 外れ値を除去するまったく異なる方法も、それが合理的である限り、問題ありません。
- アップデート:おおよその選択アルゴリズム。
これらはすべてループで実行されますが、データは毎回(わずかに)異なるため、データ構造を再利用するのは簡単ではありません。この質問に対して。
実装されたソリューション
Gronim が提案した Wikipedia 選択アルゴリズムを使用すると、実行時間のこの部分が約 20 分の 1 に短縮されました。
C# 実装が見つからなかったので、ここに思いついた方法を示します。入力が小さい場合でも Array.Sort よりも高速で、1000 要素の場合は 25 倍高速です。
public static double QuickSelect(double[] list, int k) {
return QuickSelect(list, k, 0, list.Length);
}
public static double QuickSelect(double[] list, int k, int startI, int endI) {
while (true) {
// Assume startI <= k < endI
int pivotI = (startI + endI) / 2; //arbitrary, but good if sorted
int splitI = partition(list, startI, endI, pivotI);
if (k < splitI)
endI = splitI;
else if (k > splitI)
startI = splitI + 1;
else //if (k == splitI)
return list[k];
}
//when this returns, all elements of list[i] <= list[k] iif i <= k
}
static int partition(double[] list, int startI, int endI, int pivotI) {
double pivotValue = list[pivotI];
list[pivotI] = list[startI];
list[startI] = pivotValue;
int storeI = startI + 1;//no need to store @ pivot item, it's good already.
//Invariant: startI < storeI <= endI
while (storeI < endI && list[storeI] <= pivotValue) ++storeI; //fast if sorted
//now storeI == endI || list[storeI] > pivotValue
//so elem @storeI is either irrelevant or too large.
for (int i = storeI + 1; i < endI; ++i)
if (list[i] <= pivotValue) {
list.swap_elems(i, storeI);
++storeI;
}
int newPivotI = storeI - 1;
list[startI] = list[newPivotI];
list[newPivotI] = pivotValue;
//now [startI, newPivotI] are <= to pivotValue && list[newPivotI] == pivotValue.
return newPivotI;
}
static void swap_elems(this double[] list, int i, int j) {
double tmp = list[i];
list[i] = list[j];
list[j] = tmp;
}
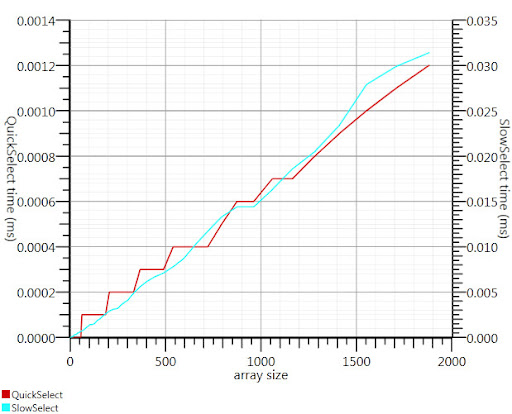
正しい方向を指し示してくれてありがとう、Gronimさん!
ベストアンサー1
Henrik のヒストグラム ソリューションは有効です。選択アルゴリズムを使用して、n 要素の配列から k 個の最大または最小の要素を O(n) で効率的に見つけることもできます。これを 95 パーセンタイルに使用するには、k=0.05n に設定し、k 個の最大要素を見つけます。
参照:
http://en.wikipedia.org/wiki/選択アルゴリズム#k_smallest_or_largest_elements の選択